Django 基本概念
基本概念
什么是前后端分离
前后端分离
- 前:浏览器
- HTML、CSS、Bootstrap、JS、JQuery、Vue、NodeJS、webpack
- 体验为主:炫酷、流畅、兼容
- 后:服务端
- Jvm、springboot、Django、flask、tornado、
- 三高:高并发、高可用、高性能
传统的不分离
用户在浏览器上发送请求,服务器端接收到请求,根据 Header 中的 token 进行用户鉴权,从数据库取出数据,处理后将结果数据填入 HTML 模板,返回给浏览器,浏览器将 HTML 展现给用户,不分离的核心就是模版,比如 Django 直接将返回数据到模版,通过模版表单将数据返回至后端
- 业务耦合较强
那这样就有一个问题,从事不分离的开发者,一般需要懂数据库、懂框架操作、懂模版前端,小型项目还好,一个人可以抗的下来,你可以加班,但如果项目较大,一个人无法独立完成,需要团队合作
- 指责划分不明确
并且不分离的情况,所有的业务、代码、逻辑都在一套服务体系内,会造成团队之间沟通混乱,代码风格不统一,每个人的前后端技能水平层次不齐的水平,出了问题找背锅的人更慢,无法快速找到罪魁祸首
- 开发成本较高
除此之外,不分离还有一个问题,现在的服务,比如一个电商平台,除了WEB端之外,还会有 IOS 端、安卓端的各种 APP,本质上这些软件 APP 用的都是同一套数据,但是现在除了每一套前端的应用界面,由于不分离的情况,还需要给每一个平台不同的 APP 开发多套后端,这个开发成本是很高的,需要很多很多的不同语言的开发者
- 服务器压力较大
此外页面的渲染本应该是在客户端完成,但是现在都是在服务端渲染好之后再返回给用户,那么在高并发的情况下,会大量占用服务器的资源
- 提高 SEO 速度,提高搜索引擎收录检索速度
当然,不分离也有好处,页面数据都是渲染好返回的,可以有效提高 SEO的速度
现在的前后端分离
数据渲染的工作在客户端浏览器,不需要服务端完成,服务端专注于提供数据
那么这就要求Django框架不需要返回一个模版页面,而是返回一套JSON数据,而由于JSON可以在多种语言中支持,是一种交互、兼容非常合适的语言格式,所以现在后台常返回的数据都为JSON格式的,这个过程也称作序列化
- 部署解耦
前后端分离再就是部署压力较小,前后端分离部署,可以分离业务,起码在后端宕机时,前端还可以正常服务
- 业务划分清晰,指责更为明确
后端工程师只需要专注于编写接口,从数据库提取数据,进行逻辑处理,并返回给前端,而前端怎么去渲染,怎么写样式,用什么前端,这都不是后端工程师需要考虑的,后端要做好的就一件事,写好接口就可以
- 开发成本较低,一套后台可以支持多套前端渲染
一般来说,一套接口编写好之后,业务相同的情况下,是可以在多种 app 端、pc 端进行渲染展示的,不需要额外开发多套耦合的服务,这就很省钱了
- SEO 优化较差,需要引入一些页面静态化手段
但是前后端分离也有不好的地方,在于页面数据的渲染是需要花费时间的,数据并不是渲染好返回给用户,所以可能会出现白屏时间,并且影响搜索引擎爬虫的检索收录
什么是restful风格
在前后端分离的应用模式里,API接口如何定义?
例如:对于后端数据库中保存了商品的信息,前端可能需要对商品数据进行增删改查,那相应的每个操作后端都需要提供一个API接口:
POST /add-goods增加商品POST /delete-goods删除商品POST /update-goods修改商品GET /get-goods查询商品信息
对于接口的请求方式与路径,每个后端开发人员可能都有自己的定义方式,风格迥异。
是否存在一种统一的定义方式,被广大开发人员接受认可的方式呢?
这就是被普遍采用的*API*的RESTful设计风格。
RestFul 规范建议
域名要有标示
Restful 风格建议,Api 服务器的域名要尽量在专用域名之下
如:百度面向用户的站点地址为https://baidu.com
那么后端的接口地址可以为
https://api.baidu.com
也可以放在连接之后
https://baidu.com/api/
路由中体现接口版本号
如果你的接口会不停的升级,那么建议你把接口的版本号维护在URL中,比如图灵机器人就是这么干的,API 的升级会把版本放入连接
https://api.baidu.com/v1/
https://baidu.com/api/v1/
http://openapi.tuling123.com/openapi/api/v2
使用合理的请求方式
对应操作,应该返回操作后的资源结果,比如获取数据,那就应该使用GET请求方式
如果是更新数据,那么建议你使用PUT或PATCH方法
- GET:获取数据
- POST:提交数据,创建数据
- PUT:提交数据,更新数据
- DELETE:删除数据
还有三个不常用的HTTP动词
- PATCH:在服务器更新(更新)资源
- HEAD:获取资源的元数据。
- OPTIONS:获取信息,关于资源的哪些属性是客户端可以改变的
提供参数过滤数据
如果数据较多,返回所有数据是不现实的,那么可以让API提供参数,进行结果返回
?limit=10:指定返回记录的数量
?offset=10:指定返回记录的开始位置。
?page=2&per_page=100:指定第几页,以及每页的记录数。
?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序。
?animal_type_id=1:指定筛选条件
使用合理的状态码
接口返回数据,还要带上合理的状态码进行标记
200 OK - [GET] # 服务器成功返回用户请求的数据
201 CREATED - [POST/PUT/PATCH] # 用户新建或修改数据成功。
202 Accepted - [*] # 表示一个请求已经进入后台排队(异步任务)
204 NO CONTENT - [DELETE] # 用户删除数据成功。
400 INVALID REQUEST - [POST/PUT/PATCH] # 用户发出的请求有错误,服务器没有进行新建或修改数据的操作
401 Unauthorized - [*] # 表示用户没有权限(令牌、用户名、密码错误)。
403 Forbidden - [*] # 表示用户得到授权(与 401 错误相对),但是访问是被禁止的。
404 NOT FOUND - [*] # 用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。
406 Not Acceptable - [GET] # 用户请求的格式不可得(比如用户请求 JSON 格式,但是只有 XML 格式)。
410 Gone -[GET] # 用户请求的资源被永久删除,且不会再得到的。
422 Unprocesable entity - [POST/PUT/PATCH] # 当创建一个对象时,发生一个验证错误。
500 INTERNAL SERVER ERROR - [*] # 服务器发生错误,用户将无法判断发出的请求是否成功
什么是接口及接口文档
API,全称是Application Programming Interface,即应用程序编程接口,我们日常中习惯简称为“接口”。其实,接口这个词大家应该不会陌生,比如我们平时比较常用的“USB接口”,就是用来存储和传输数据用的;
那什么是API呢,API事实上是在内部预先定义了函数,能够使开发人员无须明白API内部实现的机制,就能够实现某一个功能。
比如说你要实现一个手机注册的功能,那么相应地后台工程师就需要提供一个手机注册的接口,前端开发人员在调用接口实现功能的时候,只需按照既定的规则进行请求即可,不需要去理解该功能的实现逻辑。有了这么一个机制,就使得开发人员间的协作变得非常简洁、高效。
所以,你可以简单地理解为“接口决定了功能”。
接口文档又称为API文档,一般是由开发人员所编写的,用来描述系统所提供接口信息的文档。 大家都根据这个接口文档进行开发,并需要一直维护和遵守。
为什么要写接口文档? 1、项目开发过程中前后端工程师有一个统一的文件进行沟通交流开发 2、项目维护中或者项目人员更迭,方便后期人员查看、维护
如何阅读接口文档
API接口文档一般分为接口描述、接口地址、请求方法、请求参数、响应内容、错误代码、实例几个部分:
接口描述: 简单描述接口的逻辑和作用。例如说明这是一个发送消息的接口、查询天气的接口;
接口地址: 这个地址表示的是网络地址,即url,我们需要调用接口url,获取响应内容;
请求方法: 常见的请求方法为GET和POST,其他的方式见下图;
请求参数: 用来传递信息的变量。即需要请求的字段名的名称和规则:都是哪些字段,字段的类型是什么,是否必填字段等等;
- URL传参
- Headers 请求头
- Body 请求内容
响应内容: 接口返回的字段名称和规则;
错误代码: 对接口的错误用代码进行归类,以便能快速找到错误原因,解决问题;
实例: 实际调用时的响应的内容。
以阿里云API市场为例:
获取access_token
【注意】正常情况下access_token有效期为7200秒,有效期内重复获取返回相同结果,并自动续期。
调试工具:在线调试
请求方式:GET(HTTPS)
请求地址:https://oapi.dingtalk.com/gettoken?appkey=key&appsecret=secret
参数说明:
| 参数 | 类型 | 必须 | 说明 |
|---|---|---|---|
| appkey | String | 是 | 应用的唯一标识key |
| appsecret | String | 是 | 应用的密钥 |
DRF工程
drf工程搭建
安装DRF框架
pip install djangorestframework -i https://pypi.tuna.tsinghua.edu.cn/simple
配置 settings
INSTALLED_APPS = [
...
'rest_framework',
]
drf官方文档导读
这个框架提供了如下功能,让我们的代码风格更加统一,而且让你的开发工作成本更低,这个框架封装了很多很多复用的功能
- 将请求的数据转换为模型类对象
- 操作数据库
- 将模型类对象转换为响应的数据如JSON格式
- 视图封装:DRF统一封装了请求的数据为request.data以及返回数据的Response方法
- 序列化器:DRF提供了序列化器可以统一便捷的进行序列化及反序列化工作
- 认证:对用户登陆进行身份验证
- 权限:对用户权限进行认证,超级用户、普通用户、匿名用户啥的
- 限流:对访问的用户流量进行限制,减轻接口的访问压力
- 过滤:可以对列表数据进行字段过滤,并可以通过添加django-fitlter扩展来增强支持
- 排序:来帮助我们快速指明数据按照指定字段进行排序
- 分页:可以对数据集进行分页处理
- 异常处理:DRF提供了异常处理,我们可以自定义异常处理函数
- 接口文档生成:DRF还可以自动生成接口文档
序列化器,类视图,也是DRF提供的主要功能,也是我们学习的重心,也是 WEB 主要的两件事
基本视图
在drf框架中,已经封装了一款更为便捷进行接口编写的视图基类APIView,大多数情况下,都会使用这个基类进行业务视图的代码编写
Request请求
.data
DRF将request.POST、request.FILES的数据统一封装到了data属性中,其中包含了
- 解析之后的文件、非文件数据
- 对POST、PUT、PATCH请求方式解析后的数据
- 表单类型数据、JSON类型数据
from rest_framework.views import APIView
class ExampleView(APIView):
def post(self, request):
data = request.data # json/form 提交的数据
return Response({'received data': request.data})
.query_params
DRF为了更准确的表示这是从连接里取得数据,从而把request.GET的名字更换为了request.query_params,其余操作与request.GET一样,这里只是拼写更换
from rest_framework.views import APIView
class ExampleView(APIView):
def get(self, request):
data = request.query_params # get 的连接传参
return Response({'received data': request.query_params})
Response返回
目前在DRF中,我们所使用最多的就是Response这个方法,经常使用已经序列化好的数据结合Response返回
Response(data=None, status=None, template_name=None, headers=None, exception=False, content_type=None)
'''
data: 需要返回的数据
status: 状态码
headers: 头部信息
content-type: 返回数据 MIME 类型,一般不要多余设置,drf 会自动根据数据进行设置
'''
需要注意的是,在Response函数的第一个参数位置上,这个data不能是复杂结构的数据,比如ORM查询到的数据,ORM的数据需要提取出来成为Python的数据类型或者使用序列化方式将其加工才可以使用Response尽心返回
常见状态码
200 OK - [GET] # 服务器成功返回用户请求的数据
201 CREATED - [POST/PUT/PATCH] # 用户新建或修改数据成功。
202 Accepted - [*] # 表示一个请求已经进入后台排队(异步任务)
204 NO CONTENT - [DELETE] # 用户删除数据成功。
序列化
什么是JSON
这一种在各个编程语言中流通的数据格式,可以在不同的编程语言中的进行数据传递和交互
也就是用JSON传输数据可以让不同语言之间可以跨越语言不同的鸿沟,虽然 python 无法和 js 进行通信,但是通过JSON,就可以让两者进行数据通信,所以现在常见的接口返回的数据都是JSON格式
什么是序列化
序列化:就是把模型层的数据返回为JSON数据集
反序列化:就是把前端发来的JSON数据,类字典数据,变为模型层的数据
Json序列化
book_set = Book.objects.all()
books = []
for book in book_set:
books.append({
'id': book.id,
'btitle': book.btitle,
'price': book.price,
'bread': book.bread,
'bcomment': book.bcomment
})
DRF序列化
drf中提供了类似django原生中forms组件的序列化类对象,通过对模型类或数据字段进行序列化字段映射
比如一个模型类表结构是这样的
class Book(models.Model):
btitle = models.CharField(max_length=20, verbose_name="图书名称")
price = models.DecimalField(max_digits=7, decimal_places=2, verbose_name="单价")
bread = models.IntegerField(verbose_name="阅读量")
bcomment = models.IntegerField(verbose_name="评论量")
img = models.ImageField(upload_to='imgs/%Y/%m/%d', verbose_name="封面图片")
class Meta:
db_table = 'tb_book'
verbose_name = '图书'
verbose_name_plural = verbose_name
def __str__(self):
return self.btitle
那么对应的,可以创建出如下所示的序列化器
class BookSerializer(serializers.Serializer):
btitle = serializers.CharField(max_length=20, label='图书名称')
price = serializers.DecimalField(max_digits=7, decimal_places=2, label='单价')
bread = serializers.IntegerField(default=0, required=False, label='阅读量')
bcomment = serializers.IntegerField(default=0, required=False, label='评论量')
img = serializers.ImageField(label='封面图片', required=False)
这样可以更为方便的将orm遍历或拿取的单独数据进行序列化返回
books = Book.objects.all()
data = BookSerializer(books, many=True).data # 这就是经过序列化器处理好的 可以返回给前端的数据
序列化示例
一个获取所有图书的示例
from django.http.response import JsonResponse
from rest_framework.views import APIView
class BooksView(APIView):
def get(self, request):
books = Book.objects.all() # 查询所有图书
serializer = BookSerializer(books, many=True)
# 构建序列化器对象, 需要序列化的对象不止一个,需要参数 many=True
return JsonResponse(serializer.data, safe=False)
# 需要转换为Json的数据不是字典,需要设置safe=False
前后联调
以下案例主要以vue为例
前后端分离的跨域问题
安装插件
pip install django-cors-headers
修改配置信息
- 注册
corsheaders
INSTALLED_APPS = [
...
'corsheaders', # 跨域
...
]
- 添加中间件
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware', # 添加跨域中间件
'corsheaders.middleware.CorsMiddleware',
'django.middleware.common.CommonMiddleware',
# 'django.middleware.csrf.CsrfViewMiddleware', # 关闭csrf验证
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
- 配置参数,允许所有源访问
CORS_ORIGIN_ALLOW_ALL = True
axios请求
首先在Vue项目的main.js中全局配置axios
import axios from 'axios' // 导入axios
axios.defaults.baseURL = "http://127.0.0.1:8000/" // 设置axios请求的默认域名,即django服务的域名
Vue.prototype.$axios = axios // 全局挂载axios
vue数据处理
vue获取数据进行渲染删除
<template>
<div>
<!-- 三、循环展示所有作者 -->
<table>
<tr v-for="author in authorList" :key="author.id">
<td>{{ author.id }}</td>
<td>{{ author.name }}</td>
<td>{{ author.gender }}</td>
<td>{{ author.age }}</td>
<td>
<!--
内层元素的事件会从内向外依次触发, 叫做冒泡机制
想要阻止冒泡事件,需要 使用 事件修饰符 .stop
-->
<button @click.stop="delAuthor">删除</button>
</td>
</tr>
</table>
</div>
</template>
<script>
export default {
name: "AuthorList",
data() {
return {
authorList: []
}
},
methods: {
// 一、get请求所有作者
getAuthorList() {
this.$axios.get('author/')
.then(resp => {
console.log(resp.data)
this.authorList = resp.data
})
},
delAuthor(id) {
this.$axios.delete('author/' + id + '/')
.then(resp => {
// 删除成功,重新请求数据,刷新页面
this.getAuthorList();
})
.catch(err => {
console.log('删除失败')
})
},
},
mounted() {
// 二、挂载,让请求自动执行
this.getAuthorList();
}
}
</script>
axios提交
创建数据
<template>
<div>
<!-- 1. 使用v-model指定从表单获取数据 -->
图书标题: <input type="text" v-model="title">
图书价格: <input type="text" v-model="price">
<!-- 3. 使用事件绑定,将 方法和按钮进行绑定 -->
<button @click="btn">添加</button>
</div>
</template>
<script>
export default {
name: "Book",
data() {
return {
title: '',
price: ''
}
},
methods: {
btn() {
// 2. 定义方法, 使用axios发送post请求,并携带参数
this.$axios.post('book/', {'title': this.title, 'price': this.price})
.then(resp => {
// 添加成功,输出响应数据
console.log(resp.data)
})
.catch(err => {
// 添加失败,输出错误信息
console.log(err.response.data)
})
}
}
}
</script>
修改数据
<template>
<div>
<!-- 修改之前,需要有原始数据 -->
<!-- 一、修改图书之前,给表单设置默认值, 原本的图书数据 -->
<!-- 二.修改同样也需要获取用户输入的新数据 -->
图书标题: <input type="text" v-model="book.title">
图书价格: <input type="text" v-model="book.price">
<!-- 四、对按钮绑定事件 -->
<button @click="updateBook">修改</button>
</div>
</template>
<script>
export default {
name: "BookUpdate",
data() {
return {
id: 1,
book: {
title: '',
price: ''
}
}
},
methods: {
// 1.1 获取id对应的图书数据
getBook() {
this.$axios.get('book/' + this.id + '/')
.then(resp => {
// 请求成功,将请求到的图书数据赋值给data中的变量,
// 而表单和data中的数据进行双向绑定
// 给data中的数据设置默认值,表单也会有默认值
this.book.title = resp.data.title
this.book.price = resp.data.price
})
},
// 三. 定义方法,使用put提交数据
updateBook() {
this.$axios.put('book/' + this.id + '/', this.book)
.then(resp => {
console.log(resp.data)
})
}
},
mounted() {
// 1.3 挂载
this.getBook();
}
}
</script>
状态保持
前后端分离情况下的状态保持
除了使用vuex在vue中的标准解决方案外,还有类似浏览器的内部存储机制,比如
localStorage.setItem('user', this.username) // 用户名存入localStorage,以做状态保持
let username = localStorage.getItem('user') // 取出user信息,可以判断用户是否登录
序列化器
普通序列化器
Response是不能直接返回ORM数据的,所以需要我们进行序列化操作,可以通过手动将其转为字典或JSON,也可以使用DRF所提供的序列化器,我们一般建议您使用序列化器,这个更专业,更简单,并且格式更为统一
如果你经常使用的是自己去将数据封装为JSON,那么常见的代码模型就像这样
data = models.objects.all()
json_ = {}
for d in data:
json_['age'] = d.age
json_['name'] = d.name
return Response(json_)
字段多了的话,这个工作量就会越来越麻烦了,而且有关于时间(\*\DateTimeField、DateField***)等字段类型的序列化直接通过*JSON也是不行的,需要自己手动编写JSON*的序列化器,非常麻烦,于是乎 DRF 就提供了更为便捷的两种序列化器,普通序列化器与模型序列化器**
普通序列化器编写方式
from rest_framework import serializers
普通序列化器,可以按照给定字段,将所匹配的ORM数据字段转换为JSON数据,不光可以对一条数据,也可以对一个QuerySet所对应的结果集
比如一个课程表有如下一些字段
class Course(models.Model):
name = models.CharField(max_length=20, verbose_name='课程名字')
created = models.DateField(verbose_name='课程创建时间')
def __str__(self):
return self.name
测试数据可以通过数据库手动添加 那么普通序列化器就可以定义如下,按照模型类字段支持即可,非常简单
class CourseSer(serializers.Serializer):
name = serializers.CharField(max_length=20)
created = serializers.DateField(auto_now_add=True)
普通的序列化器,不光可以为数据库模型类定义,也可以为非数据库模型类的数据定义,只是这里为模型类定义时,需要根据模型类字段一一映射
普通序列化器序列化
序列化就是将ORM数据放入序列化器加工,诞生出JSON数据对象,序列化器对象的 data 属性即为处理好的 JSON 数据对象
- 单条数据的序列化
单挑数据的序列化很简单,直接通过序列化器类对象的参数instance传入查询得到的结果即可
object = models.objects.get(pk=1)
ser_data = Serializer(instance=object)
ser.data # 这就是这一条数据的 JSON 结果
- 多条数据的序列化
如果使用像filter、all这样的一些ORM方法,获取到的是QuerySet结果集,不是单独数据对象,那么使用序列化器时,需要传入many=True参数,用来表示:哇哦~
objects = models.objects.all()
ser_data = Serializer(instance=objects, many=True)
ser_data.data # 这就是这一群数据的 JSON 结果
普通序列化器反序列化创建
反序列化的概念很简单,就是把JSON等数据变为ORM数据对象,甚至是入库或者是修改
DRF要求序列化器必须对数据进行校验,才能获取验证成功的数据或保存成模型类对象
在操作过程中,反序列化首先需要通过data**传参**
接着调用
is_valid
进行校验,
验证成功
返回
True
,反之返回
False
- 如果校验失败,还可以通过结果的errors**属性**返回错误值
- is_valid调用后方法会进行字段属性(max_value=10)的校验、自定义的校验等等
对校验过后的对象调用
save
方法,这个
save
方法会触发
序列化器
中的
create
方法
- 普通序列化器中,create方法默认是没有实现的,需要手动根据模型类进行编写
data = {
'name':"张三",
...
}
ser = Serializer(data=data)
if ser.is_valid():
ser.save() # 只传 data 参数的时候,save 方法会触发序列化器器中的 create 方法
比如现在,还是之前练习需要提交数据创建课程的接口,此时可以这么做
为了能够保证数据成功入库,默认的普通序列化器是不具备入库功能的,需要编写create方法
class CourseSer(serializers.Serializer):
name = serializers.CharField(max_length=20)
created = serializers.DateField()
def create(self, validated_data):
object = Course.objects.create(
**validated_data
)
return object
成功之后,就可以通过像之前一样的数据提交,编写视图完成数据入库,序列化器可以直接处理request所提交的数据data,并且可以剔除在request.data中其他多余的字段,只会处理序列化器里的字段
class CourseCreate(APIView):
def post(self, request):
ser = CourseSer(data=request.data)
if ser.is_valid():
ser.save()
error = ser.errors
return Response({'msg': error if error else 'success'})
普通序列化器反序列化更新
反序列化经过校验的数据,不光可以创建数据,还可以更新数据呢
- 更新首先需要一个已经存在的数据,所以需要通过instance参数传递已有的一个ORM对象
- 还需要待更新的新值,那么就需要传data参数
- 之后同样需要is_valid方法调用,检查即将更新进入的数据是否合法
- 最终save触发序列化器中的update方法
默认普通序列化器是没有自带对于数据的更新方法的,现在需要在序列化器里创建update方法
class CourseSer(serializers.Serializer):
name = serializers.CharField(max_length=20)
created = serializers.DateField()
def update(self, instance, validated_data):
# instance 要更新的数据,validated_data 是新数据
instance.name = validated_data.get('name', instance.name)
instance.type = validated_data.get('create', instance.type)
instance.save()
return instance
然后通过PUT传递要更新数据的ID,以及更新后的值,来为某条数据更新
class CourseUpdate(APIView):
def put(self, request):
id_ = request.data.get("id") # 获取当前更新数据的 ID
try:
course = Course.objects.get(pk=id_)
except Course.DoesNotExist:
return Response({'msg': '更新失败,不存在这条数据'})
ser = CourseSer(instance=course, data=request.data)
if ser.is_valid():
ser.save()
error = ser.errors
return Response({'msg': error if error else 'success'})
模型序列化器
模型序列化器编写方式
之前的序列化器,很明显可以感觉到,如果模型类字段少了,还行,但是模型字段越来越多,那么开发者在序列化器里所要复刻的字段也要越来越多,很麻烦奥
而且还得手动实现update和create方法,而且光写了序列化器字段还不行,还得有字段属性
于是乎,有了现在的与模型类关联的序列化器,可以更加方便的进行字段映射以及内置方法的编写,简直是太棒了
模型类关联序列化器大概总结有如下三个特性,一个缺点
- 特点
- 基于模型类自动生成一系列字段
- 自动生成的系列字段,同时还包含unique、max_length等属性校验
- 包含默认的create和update的实现
- 缺点
- 不会自动映射模型类字段的default属性
那么模型类关联的序列化器用啥呢?用的是新的序列化器基类
from rest_framework.serializers import ModelSerializer
比如一个商品模型类
class Goods(models.Model):
title = models.CharField(max_length=200, verbose_name='商品标题')
description = models.TextField(verbose_name='描述')
inventory = models.IntegerField(default=0, verbose_name='库存量')
price = models.DecimalField(
max_digits=10, decimal_places=2, verbose_name='商品价格')
cover = models.CharField(max_length=200, verbose_name='封面图')
issale = models.BooleanField(default=False, verbose_name='是否促销')
saleprice = models.DecimalField(
max_digits=10, decimal_places=2, verbose_name='促销价格')
ishow = models.BooleanField(default=True,verbose_name='是否上架')
createtime = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
def __str__(self):
return self.title
class Meta:
db_table = 'goods'
按照之前的普通序列化写法,你需要同步一个字段,并将字段属性也要记得同步,非常麻烦 但通过与模型类关联的序列化器就很简单了
- 首先通过继承ModelSerializer基类
- 通过序列化器元类属性中的model属性关联模型类
- 通过序列化器元类属性中的fields属性指明序列化器需要处理的字段
class GoodsSer(serializers.ModelSerializer):
class Meta:
model = Goods
fields = '__all__' # 指明所有模型类字段
# exclude = ('createtime',) # 排除掉的字段
# read_only_fields = ('title','description') # 只用于序列化的字段
# fields = ('title','description','inventory') # 手动指明字段
# extra_kwargs = {
# 'price':{'min_value':0, 'required':True},
# } # 修改原有字段的选项参数
模型类关联的序列化器和普通的序列化器使用方法一样
使用序列化器返回当前所有的商品数据,还是像之前一样传入instance参数即可,还要记得由于是多个商品,不是单独数据,要记得加many=True参数
模型序列化器反序列化创建、更新
模型序列化器的创建就更简单了,不需要手动实现create方法,大致流程如下:
- 为序列化器绑定数据,ser=Serializer(data=request.data)
- 校验数据,ser.is_valid()
- 存储入库,ser.save()
创建商品接口
class GoodsCreate(APIView):
def post(self, request):
ser = GoodsSer(data=request.data)
if ser.is_valid():
ser.save()
error = ser.errors
return Response({'msg': error if error else 'success'})
注意:反序列化自动生成的字段属性中,不会包含原始模型类字段中的default字段属性
更新某一个商品数据,模型序列化器也是自带了update方法
更细商品接口
class GoodsUpdate(APIView):
def put(self, request):
id_ = request.data.get("id")
try:
goods = Goods.objects.get(pk=id_)
except Goods.DoesNotExist:
return Response({'msg': '更新失败,不存在这条数据'})
ser = GoodsSer(instance=goods, data=request.data)
if ser.is_valid():
ser.save()
error = ser.errors
return Response({'msg': error if error else 'success'})
模型序列化器与普通序列化器的对比
序列化
时,将模型类对象传入
instance
参数
- 序列化结果使用序列化器对象的data**属性**获取得到
反序列化创建
时,将要被
反序列化
的数据传入
data
参数
- 反序列化一定要记得先使用is_valid校验
反序列化更新时,将要更新的数据对象传入instance参数,更新后的数据传入data**参数**
模型序列化器比普通序列化器更加方便,自动生成序列化映射字段,create方法等
关联外键序列化,字段属性外键为多时要记得加many=True
外键序列化
之前的序列化,只是简单的对一张表进行处理,那么如果遇到一对一,多对一,多对多的情况该咋序列化呢,我们来看看
比如现在有两张很常见的关联表,老师表和学生表
- 一个老师可以有一群学生,但是一个学生只能有一个老师
class Teacher(models.Model):
name = models.CharField(max_length=30, verbose_name='老师名')
age = models.IntegerField(verbose_name='年纪')
def __str__(self):
return self.name
class Student(models.Model):
name = models.CharField(max_length=30, verbose_name='学生名')
teacher = models.ForeignKey(
Teacher, on_delete=models.SET_NULL,
null=True, blank=True,
verbose_name='关联老师'
)
def __str__(self):
return self.name
学生表中,包含外键 teacher,外键可以通过如下一些方式进行序列化
PrimaryKeyRelatedField
将关联表的主键作为结果返回,使用 PrimaryKeyRelatedField字段,该字段需要包含 queryset或 read_only属性
设置 read_only代表该字段不进行反序列化校验
class StudentSer(serializers.ModelSerializer):
teacher = serializers.PrimaryKeyRelatedField(read_only=True)
class Meta:
model = Student
fields = '__all__'
编写返回一个学生的接口
class StudentDetail(APIView):
def get(self, request):
id_ = request.query_params.get('id')
# 通过 GET 传参获取当前学生 ID
try:
stu = Student.objects.get(pk=id_)
except Student.DoesNotExist:
return Response({'error': '查不到结果'})
ser = StudentSer(instance=stu)
return Response(ser.data, status=200)
返回的数据类似如下效果
{
"id": 1,
"teacher": 1,
"name": "小红"
}
StringRelatedField
将关联表的*str*方法作为结果返回
class StudentSer(serializers.ModelSerializer):
teacher = serializers.StringRelatedField()
class Meta:
model = Student
fields = '__all__'
接口返回效果如下
{
"id": 1,
"teacher": "张老师", # teacher 表的__str__方法所返回的
"name": "小红"
}
SlugRelatedField
使用关联表的指定字段作为结果返回
class StudentSer(serializers.ModelSerializer):
teacher = serializers.SlugRelatedField(read_only=True, slug_field='name')
class Meta:
model = Student
fields = '__all__'
效果就很直观了,返回的就是 slug_field字段所对应的模型层里这个字段代表的值
{
"id": 1,
"teacher": 20,
"name": "小红"
}
嵌套序列化器关联
上面几种办法只能返回单独定义的字段,适合某些返回数据简单的情况下,如果希望能返回当前关联字段的详细数据,那么可以通过额外定义关联表的序列化器,让当前外键字段使用关联表序列化器即可
class TeacherSer(serializers.ModelSerializer):
class Meta:
model = Teacher
fields = '__all__'
class StudentSer(serializers.ModelSerializer):
teacher = TeacherSer(read_only=True)
class Meta:
model = Student
fields = '__all__'
此时外键 teacher 字段所对应的序列化器是关联表的序列化器,需要返回的关联表数据可以通过另外这个序列化器进行单独定义,返回的接口数据如下
{
"id": 1,
"teacher": {
"id": 1,
"name": "张老师",
"age": 20
},
"name": "小红"
}
外键反向序列化
反向关联:model_set
如果查询一个老师,想返回所有关联这个老师的学生们,通过序列化器可以使用关联表模型_set字段完成,还要记得由于是多个学生关联,所以这个序列化字段要加 many=True属性
查询所有老师的信息,并且连带返回所有老师所拥有的学生
class TeacherFullDetail(APIView):
def get(self, request):
teachers = Teacher.objects.all()
ser = TeacherSerializer(instance=teachers, many=True)
return Response(ser.data, status=200)
PrimaryKeyRelatedField
使用反向关联表的主键进行返回
class TeacherSerializer(serializers.ModelSerializer):
student_set = serializers.PrimaryKeyRelatedField(read_only=True, many=True)
class Meta:
model = Teacher
fields = '__all__'
结果如下,反向关联字段使用关联表的主键进行返回, 并且封装在一个列表中
[
{
"id": 1,
"student_set": [
1,
2
],
"name": "张老师",
"age": 20
},
{
"id": 2,
"student_set": [],
"name": "李老师",
"age": 18
}
]
StringRelatedField
通过关联表*str*方法进行返回
class TeacherSerializer(serializers.ModelSerializer):
student_set = serializers.StringRelatedField(read_only=True, many=True)
class Meta:
model = Teacher
fields = '__all__'
结果就是反向关联外键的结果列表中包含的都是学生表*str*方法返回的结果
[
{
"id": 1,
"student_set": [
"小红",
"小明"
],
"name": "张老师",
"age": 20
},
{
"id": 2,
"student_set": [],
"name": "李老师",
"age": 18
}
]
SlugRelatedField
通过指定表中字段作为序列化字段的结果
class TeacherSerializer(serializers.ModelSerializer):
student_set = serializers.SlugRelatedField(read_only=True, slug_field='name', many=True)
class Meta:
model = Teacher
fields = '__all__'
结果如下所示
[
{
"id": 1,
"student_set": [
"小红",
"小明"
],
"name": "张老师",
"age": 20
},
{
"id": 2,
"student_set": [],
"name": "李老师",
"age": 18
}
]
嵌套序列化器关联
使用关联表的单独序列化器,和关联外键序列化器一样样的
class StudentSer(serializers.ModelSerializer):
class Meta:
model = Student
fields = '__all__'
class TeacherSerializer(serializers.ModelSerializer):
student_set = StudentSer(many=True, read_only=True)
class Meta:
model = Teacher
fields = '__all__'
效果就是学生的反向外键成为了具体的数据信息,而不是单独以指定字段或方式进行维护定义的
[
{
"id": 1,
"student_set": [
{
"id": 1,
"name": "小红",
"teacher": 1
},
{
"id": 2,
"name": "小明",
"teacher": 1
}
],
"name": "张老师",
"age": 20
},
{
"id": 2,
"student_set": [],
"name": "李老师",
"age": 18
}
]
外键字段反序列化
还是上面的例子,反序列化创建一个学生,使用模型序列化器很简单,默认是接受外键关联表的主键数据作为创建的依据,也就是代表着外键可以不像原始使用 ORM一样得传一个外键表数据 object,而是直接传一个 id就可以了
主键传值
在 postman或其他手段进行测试时,直接传老师 id、学生名、及其他所需字段即可
学生反序列化器不需要写任何字段,默认的关联字段会接受一个 id数据作为校验依据并创建
class StudentSer(serializers.ModelSerializer):
class Meta:
model = Student
fields = '__all__'
创建接口如下
class StudentCreate(APIView):
def post(self, request):
ser = StudentSer(data=request.data)
if ser.is_valid():
ser.save()
error = ser.errors
return Response({'msg': error if error else 'success'})
postman 测试时,只需要传如下数据即可
{
"teacher": "2", # 外键直接传入 id 即可
"name": "小黑"
}
外界传值
在序列化器使用过程中,可以通过 context 传递参数,这个参是一个字典数据对象,设置一些额外的值,使你的序列化器可以更灵活的操作参数
Serializer(instance=objects, data=request.data,context={})
现在序列化器不会自动验证接受并处理 teacher字段,需要手动维护
class StudentSer(serializers.ModelSerializer):
teacher = TeacherSer(read_only=True)
# read_only 将该字段设置为只是序列化使用,不会经过反序列化处理
class Meta:
model = Student
fields = '__all__'
# fields = 'name' # 指明字段也可以实现屏蔽 teacher 字段反序列化的作用
通过之前的 Json数据提交 teacher与 name字段,此时 teacher是无效的,不会被反序列化处理 但是我们可以单独把提交的 teacher提取出来,传入 context参数,重写 create方法,在 create方法中获取 context参数,拿到 teacher,看下面的新接口
新的序列化器是这样的
class StuSer(serializers.ModelSerializer):
teacher = TeacherSer(read_only=True)
def create(self, validated_data):
validated_data['teacher_id'] = self.context.get('teacher')
ModelClass = self.Meta.model
object = ModelClass._default_manager.create(**validated_data)
return object
class Meta:
model = Student
fields = '__all__'
视图稍微处理一下 teacher数据
class StuCreate(APIView):
def post(self, request):
teacher = request.data.get('teacher')
ser = StuSer(data=request.data, context={'teacher': teacher})
if ser.is_valid():
ser.save()
error = ser.errors
return Response({'msg': error if error else 'success'})
反序列化校验
在之前的操作中,我们已经接触到了 update 以及 create 方法进行更新创建的反序列化操作,验证主要通过调用is_valid方法触发
其实在反序列化过程中,还可以通过由 DRF 所指定的一系列校验方法对字段进行更加细致的验证,比如对于密码的强弱判断,直接通过字段属性是无法做到的,但是可以放在以下所提供的校验方法中,自定义其校验规则
validate_字段
这种办法是单独字段的校验,可以对序列化器类对象所写的字段进行判断验证
- 在序列化器里定义校验字段的钩子方法:validate_字段
- 获取字段的数据,就是参数接收到的value值
- 验证不通过,抛出异常:raise serializers.ValidationError("校验不通过的说明")
- 验证通过,返回字段数据
def validate_name(self, value):
if len(value) == 1:
raise serializers.ValidationError('名字长度无法为1')
return value
validate
多字段联合校验,这种校验方法是可以一次性获取到所有序列化器字段里的全部值,可以进行一个统一整体的校验判断
- 在序列化器定义validate方法,参数为attrs
- attrs是所有数据组成的字典
- 不符合抛出异常:raise serializers.ValidationError("校验不通过的说明")
- 如果校验全部成功,那么返回attrs参数对象
def validate(self,attrs):
name = attrs.get('name')
if name != '张三':
raise serializers.ValidationError('抱歉,不是张三不让注册')
return attrs
验证器
封装重复校验规则,使用函数机制,定义校验规则,然后将函数作用至序列化器的字段上
def my_name_validate(value):
if value != '张三':
raise serializers.ValidationError('你不是张三,不可以创建')
else:
return value
生效该验证器
name = serializers.CharField(
max_length=30,
validators=[my_name_validate] # 生效校验器,可以有多个
)
权重:验证器方法 > validate_字段 > validate
GenericAPIView
GenericAPIView是什么
GenericAPIView继承自 APIVIew,增加了对于列表视图和详情视图可能用到的通用支持方法,通常使用时,可搭配一个或多个Mixin扩展类,来实现其他更加高级的功能,总结来说 GenericAPIView 是有关数据管理的基类,未来还会学习有关方法操作的基类
先来耍耍 GenericAPIView
[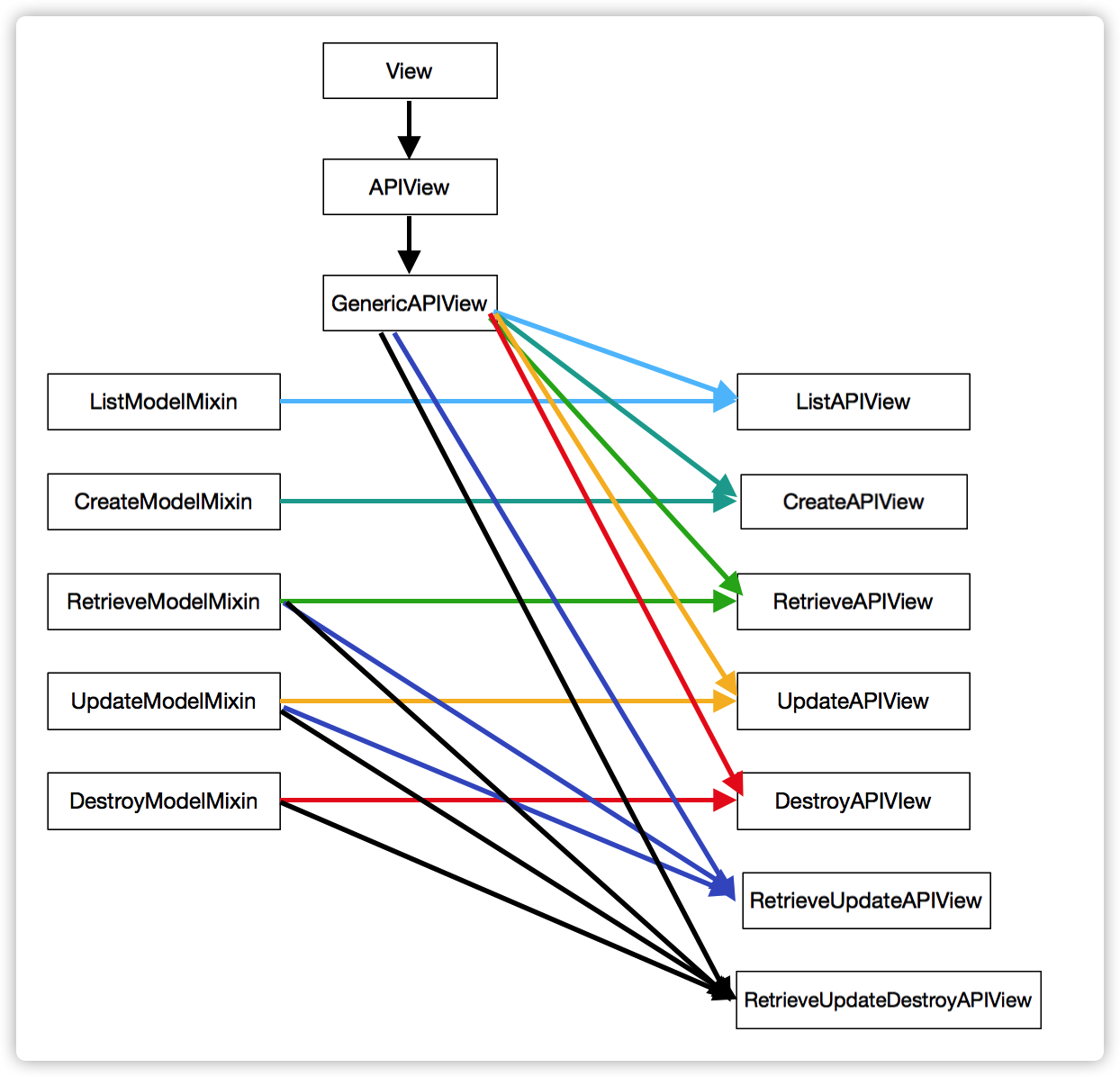
image.png
from rest_framework.generics import GenericAPIView
GenericAPIView内部属性
这个基类内置的了如下一些属性,其中一些是专门为列表视图进行返回的,一些是详情视图使用,还有一些列表与详情通用的,这些属性可以帮助我们进行序列化及反序列化的操作
列表、详情视图通用属性
queryset
*=
\
objects.all\/**.filter/
.order_by- 列表视图要操作的查询结果对象
serializer_class
=
Serializer- 视图中会使用到的序列化器,一般都是针对于上一个queryset所指定的
列表视图单独属性
- pagination_class
- 分页控制类,进行分页设置
- filter_backends
- 过滤控制后端,可以对数据进行字段过滤
详情页视图单独属性
- lookupurlkwarg
- 动态路由传递的参数命名
- lookup_field
- 过滤的orm参数
列表与详情视图通用方法
- get_queryset(self)
- 返回视图使用的查询集,是列表视图与详情视图获取数据的基础
- 默认返回queryset属性,支持重写
- getserializerclass(self)
- 返回序列化器类,默认返回serializer_class,可以重写
- get_serializer(self, args, `\kwargs`)
- 返回
详情页视图单独方法
- get_object(self)
- 返回详情视图所需的模型类数据对象,默认使用lookup_field参数来过滤queryset。 在试图中可以调用该方法获取详情信息的模型类对象
- 若详情访问的模型类对象不存在,会返回404,如果访问到多个重复,也会报错,默认使用get方法进行orm查询
- 该方法会默认使用 APIView 提供的checkobjectpermissions方法检查当前对象是否有权限被访问
- 获取全部数据
class List(GenericAPIView):
serializer_class = Ser
queryset = User.objects.all()
def get(self, request):
data = self.get_queryset()
ser = self.get_serializer(instance=data, many=True)
return Response(ser.data)
- 获取单个数据
class Detail(GenericAPIView):
serializer_class = Ser
queryset = User.objects.all()
lookup_url_kwarg = 'id' # 路由命名的参数
lookup_field = 'pk' # 过滤的orm参数
def get(self, request, id):
object = self.get_object()
ser = self.get_serializer(instance=object)
return Response(ser.data)
- 动态路由的定义
path('detail/<int:id>/', Detail.as_view()),
# 动态路由的id对应 lookup_url_kwarg
- 访问时的 URL
http://127.0.0.1:8000/detail/1/
混入类与扩展类
混入类的功能划分
GenericAPIView只是提供了数据,对应的访问功能是没有实现的,所以DRF还有五个提供方法的混入类,可以完成基本增删改查功能,我们也叫Mixin 混入类,通过GenericAPIView与混入类的多继承,可以实现更加复杂的接口功能,GenericAPIView提供数据,而混入类提供操作
ListModelMixin
- 列表视图扩展类,提供list(request, `args
,kwargs`)*方法快速实现列表视图 - 默认返回200状态码
- 该Mixin的 list 方法会对数据进行过滤和分页
CreateModelMixin
- 创建视图扩展类,提供create(request, `args
,kwargs`)*方法快速实现创建资源的视图 - 成功返回201状态码。
- 如果序列化器对前端发送的数据验证失败,返回 400错误
RetrieveModelMixin
- 详情视图扩展类,提供retrieve(request, `args
,kwargs`)*方法进行单独数据的返回 - 如果详情数据存在,返回200, 否则返回404
UpdateModelMixin
- 更新视图扩展类,提供update(request, `args
,kwargs`)*方法 - 同时提供partial_update(request, `args
,kwargs`)*方法,可以实现局部更新。 - 成功返回200,序列化器校验数据失败时,返回400错误
DestroyModelMixin
删除视图扩展类,提供destroy(request, args, kwargs)*方法
可以快速实现删除一个存在的数据对象
成功返回204,不存在返回404
混入类与GenericAPIView的组合使用
ListModelMixin
class ListView(ListModelMixin, GenericAPIView):
queryset = Model.objects.all()
serializer_class = Ser
def get(self, request):
return self.list(request)
CreateModelMixin
class CreateSer(serializers.ModelSerializer):
class Meta:
model = model
fields = '__all__'
class CreateView(GenericAPIView, CreateModelMixin):
serializer_class = CreateSer
def post(self, request):
return self.create(request)
RetrieveModelMixin
以lookup_field为 orm 过滤字段,查询lookupurlkwarg对应值的一条数据详情,需要提供queryset参数作为查询的位置
class DetailView(GenericAPIView, RetrieveModelMixin):
queryset = model.objects.all()
serializer_class = DetailSer
lookup_field = 'pk'
lookup_url_kwarg = 'pk'
def get(self, request, pk):
return self.retrieve(request)
- 设置的路由及访问的路由如下所示
path('detailview/<int:pk>/', DetailView.as_view()),
# http://127.0.0.1:8000/detailview/1/
UpdateModelMixin
实现更新的话也需要lookup_field和lookupurlkwarg来确定被更新数据,使用 put/post 等方式提交数据即可,对比创建的混合类
class UpdateView(GenericAPIView, UpdateModelMixin):
queryset = model.objects.all()
serializer_class = UpdateSer
lookup_field = 'pk' # 被更新数据过滤字段
lookup_url_kwarg = 'pk' # 被更新数据过滤条件参数值
def put(self, request, pk):
return self.update(request)
请求该视图时,不光需要链接传参数,还需要在请求体中提供更新后的数据
# put
http://127.0.0.1:8000/updateview/1/
{
"name":...
"age": ...
}
注意:如果需要对序列化器字段进行局部更新,而不是所有数据都会更新,那么可以在update参数位置传递partial参数,传递为True
self.update(request,partial=True)
DestroyModelMixin
比如删除一个已存在数据,和更新一样,需要有数据的过滤条件,不传就是用固定那套 pk 的机制查询
class DeleteView(GenericAPIView, DestroyModelMixin):
queryset = model.objects.all()
def delete(self, request, pk):
return self.destroy(request)
扩展类的应用
CreateAPIView
- 提供post方法,可以创建一条数据
继承自:GenericAPIView、CreateModelMixin
class TeacherCreateView(CreateAPIView):
serializer_class = TeacherCreateSer
ListAPIView
- 提供get方法,可以获取多条数据
继承自:GenericAPIView、ListModelMixin
class TeacherListView(ListAPIView):
queryset = Teacher.objects.all() # 你要序列化的哪些数据结果
serializer_class = TeacherListSer # 用什么序列化器
RetireveAPIView
- 提供get方法,获取某个具体数据的详情
继承自:GenericAPIView、RetrieveModelMixin
class TeacherDetailView(RetrieveAPIView):
lookup_field = 'pk' # 数据库里的字段
lookup_url_kwarg = 'id' # 过滤字段的条件,从路由传参数过来的
queryset = Teacher.objects.all()
serializer_class = TeacherDetailSer
DestoryAPIView
提供 delete 方法,可以删除某条存在数据
继承自:GenericAPIView、DestoryModelMixin
class TeacherDestoryView(DestroyAPIView):
lookup_field = 'pk' # 数据库里的字段
lookup_url_kwarg = 'id' # 过滤字段的条件,从路由传参数过来的
queryset = Teacher.objects.all()
UpdateAPIView
- 提供 put 和 patch 方法,可以更新或者局部更新某条数据
继承自:GenericAPIView、UpdateModelMixin
class TeacherUpdateView(UpdateAPIView):
lookup_field = 'pk' # 数据库里的字段
lookup_url_kwarg = 'id' # 过滤字段的条件,从路由传参数过来的
queryset = Teacher.objects.all()
serializer_class = TeacherUpdateSer
ListCreateAPIView
- 提供 post 和 get 方法,可以创建一条数据,或获取列表数据
继承自:GenericAPIView、CreateModelMixin、ListModelMixin
class TeacherListCreateView(ListCreateAPIView):
queryset = Teacher.objects.all()
serializer_class = TeacherListCreateSer
# 共用一个序列化器同时实现创建和数据展示
RetrieveUpdateAPIView
- 提供 get、put、patch 方法,可以获取一条数据详情,也可以更新一条数据
继承自:GenericAPIView、RetrieveModelMixin、UpdateModelMixin
class TeacherRetrieveUpdateView(RetrieveUpdateAPIView):
lookup_field = 'pk' # 数据库里的字段
lookup_url_kwarg = 'id' # 过滤字段的条件,从路由传参数过来的
queryset = Teacher.objects.all()
serializer_class = TeacherRetrieveUpdateSer
RetrieveDestroyAPIView
- 提供 get 和 delete 方法,可以获取和删除一条已存在数据
继承自:GenericAPIView、RetrieveModelMixin、DestoryModelMixin
class TeacherRetrieveDestroyView(RetrieveDestroyAPIView):
lookup_field = 'pk' # 数据库里的字段
lookup_url_kwarg = 'id' # 过滤字段的条件,从路由传参数过来的
queryset = Teacher.objects.all()
serializer_class = TeacherDeatilSer
RetrieveUpdateDestoryAPIView
- 提供 get、put、patch、delete 方法,啥也能干
继承自:GenericAPIView、RetrieveModelMixin、UpdateModelMixin、DestoryModelMixin
class TeacherAll(RetrieveUpdateDestroyAPIView):
lookup_field = 'pk' # 数据库里的字段
lookup_url_kwarg = 'id' # 过滤字段的条件,从路由传参数过来的
queryset = Teacher.objects.all()
serializer_class = TeacherRetrieveUpdateSer
视图集
视图集简单来说就是一群视图逻辑操作的功能合集,并可采用路由映射的方式进行功能选择,编写的内置逻辑方法不再是使用请求命名,而是使用功能来进行命名
视图集类不再实现 get、post等方法,而是实现动作 action如 list、create等,视图集只在使用 as_view方法的时候,才会将 action动作与具体请求方式对应上
比如编写一个最基本的视图集
from django.contrib.auth.models import User
from django.shortcuts import get_object_or_404
from myapps.serializers import UserSerializer
from rest_framework import viewsets
from rest_framework.response import Response
class UserViewSet(viewsets.ViewSet):
"""
A simple ViewSet for listing or retrieving users.
"""
def list(self, request):
queryset = User.objects.all()
serializer = UserSerializer(queryset, many=True)
return Response(serializer.data)
def retrieve(self, request, pk=None):
queryset = User.objects.all()
user = get_object_or_404(queryset, pk=pk)
serializer = UserSerializer(user)
return Response(serializer.data)
那么他的路由映射不是之前的直接 as_view,还要对应采取对应请求进行映射
path('userlist/', UserViewSet.as_view({'get': 'list'})),
path('userdetail/', UserViewSet.as_view({'get': 'retrieve'})
ViewSet
继承自 APIView,作用也与 APIView基本类似,提供了身份认证、权限校验、流量管理等
在 ViewSet中,没有提供任何动作 action方法,需要我们自己实现 action方法
说白了,ViewSet只是让我们可以在路由配置的地方可以进行请求映射,其他也没啥卵用,属于最基础的视图集基类
class ViewSet(ViewSetMixin, views.APIView):
"""
The base ViewSet class does not provide any actions by default.
"""
pass
- 就像下面写成这个样子
class ModelViewSet(viewsets.ViewSet):
"""
Example empty viewset demonstrating the standard
actions that will be handled by a router class.
If you're using format suffixes, make sure to also include
the `format=None` keyword argument for each action.
"""
def list(self, request):
pass
def create(self, request):
pass
def retrieve(self, request, pk=None):
pass
def update(self, request, pk=None):
pass
def partial_update(self, request, pk=None):
pass
def destroy(self, request, pk=None):
pass
- 配置路由
path('viewset/', ModelViewSet.as_view(
{'get': 'list', 'post': 'create'}
)),
path('viewset/<int:pk>/', ModelViewSet.as_view(
{
'get': 'retrieve',
'put','update',
'patch': 'partial_update',
'destroy': 'destroy'
}
))
GenericViewSet
继承自 GenericAPIView,作用也与 GenericAPIView类似,提供了 get_object、get_queryset等方法便于列表视图与详情信息视图的开发
class GenericViewSet(ViewSetMixin, generics.GenericAPIView):
"""
The GenericViewSet class does not provide any actions by default,
but does include the base set of generic view behavior, such as
the `get_object` and `get_queryset` methods.
"""
pass
- 那么就可以很轻松的来定义属于你自己的一个 GenericAPIView例子,由于 GenericAPIView只是提供了数据的容器,并没有实现 action方法,所以我们所编写的 action还是得自己去比实现数据处理逻辑
from rest_framework.viewsets import GenericViewSet
from rest_framework import status
class ModelGenericViewSet(GenericViewSet):
queryset = model.objects.all()
serializer_class = Serializer
lookup_url_kwarg = 'pk'
lookup_field = 'pk'
def list(self,request):
data = self.get_queryset()
serializer = self.get_serializer(instance=data, many=True)
return Response(serializer.data)
def retrieve(self, request):
instance = self.get_object()
serializer = self.get_serializer(instance=instance)
return Response(serializer.data)
def create(self, request):
serializer = self.get_serializer(data=request.data)
serializer.is_valid(raise_exception=True)
serializer.save()
return Response(
serializer.data,
status=status.HTTP_201_CREATED
)
def put(self,request):
instance = self.get_object()
serializer = self.get_serializer(instance=instance,data=request.data)
serializer.is_valid(raise_exception=True)
instance = serializer.save()
return instance
def destroy(self, request):
instance = self.get_object()
instance.delete()
return Response(status=status.HTTP_204_NO_CONTENT)
ModelViewSet
在 ModelViewSet从类继承 GenericAPIView,并包括用于各种动作实现方式中,通过在各种混入类的行为混合,包含了.list、.retrieve、.create、.update、.partial_update、和.destroy等方法,继承 ListModelMixin、RetrieveModelMixin、CreateModelMixin、UpdateModelMixin、DestroyModelMixin
需要至少提供 queryset和 serializer_class属性
class ModelViewSet(mixins.CreateModelMixin,
mixins.RetrieveModelMixin,
mixins.UpdateModelMixin,
mixins.DestroyModelMixin,
mixins.ListModelMixin,
GenericViewSet):
"""
A viewset that provides default `create()`, `retrieve()`, `update()`,
`partial_update()`, `destroy()` and `list()` actions.
"""
pass
- 这样具备全部混入类的视图类,只要提供对应数据属性即可完成功能
from rest_framework.viewsets import ModelViewSet
class BookModelViewSet(ModelViewSet):
queryset = Book.objects.all()
lookup_field = 'pk'
lookup_url_kwarg = 'pk'
serializer_class = BookSer
- 路由设置
path('modelviewset/',BookModelViewSet.as_view(
{'get':'list','post':'create'}
)),
path('modelviewset/<int:pk>/',BookModelViewSet.as_view(
{'get':'retrieve','put':'update','detele':'destroy'}
)),
ReadOnlyModelViewSet
该 ReadOnlyModelViewSet班也继承 GenericAPIView,但只是提供了读取数据的操作,含有的 action 有 list和 retrieve
需要至少提供 queryset和 serializer_class属性
class ReadOnlyModelViewSet(mixins.RetrieveModelMixin,
mixins.ListModelMixin,
GenericViewSet):
"""
A viewset that provides default `list()` and `retrieve()` actions.
"""
pass
- 由于只是获取数据,只能是具备 retrieve和 list方法
from rest_framework.viewsets import ReadOnlyModelViewSet
class BookReadOnlyModelViewSet(ReadOnlyModelViewSet):
queryset = Book.objects.all()
lookup_field = 'pk'
lookup_url_kwarg = 'pk'
serializer_class = BookSer
- 路由映射只需要写具备的方法即可
path('readonlymodelviewset/',
BookReadOnlyModelViewSet.as_view(
{'get': 'list'}
)),
path('readonlymodelviewset/<int:pk>/', BookReadOnlyModelViewSet.as_view(
{'get': 'retrieve'}
)),
自定义视图集基类
创建基础视图集类,提供create,list和retrieve操作,继承GenericViewSet和混入所需的操作
from rest_framework import mixins
class CreateListRetrieveViewSet(mixins.CreateModelMixin,
mixins.ListModelMixin,
mixins.RetrieveModelMixin,
viewsets.GenericViewSet):
"""
A viewset that provides `retrieve`, `create`, and `list` actions.
To use it, override the class and set the `.queryset` and
`.serializer_class` attributes.
"""
pass
自定义视图集动作
出了在视图集内容所提供的内置方法之外,还可以手动编写新的功能视图函数来完成更为复杂的业务逻辑,比如实现获取一些特定条件下的数据,那么可以在视图集中直接定义该方法,以一定过滤条件获取数据并序列化返回即可
class BookModelViewSet(ModelViewSet):
serializer_class = BookSerializer
queryset = Book.objects.all()
# 获取一定条件的书籍,比如ID大于5的
def more_than_5(self, request):
data = self.get_queryset().filter(id__gt=5)
serializer = self.get_serializer(instance=data, many=True)
return Response(serializer.data)
- 对自定义实现的动作方法进行映射
path('bookthan5/',
BookModelViewSet.as_view(
{'get': 'more_than_5'})
),
视图集序列化器选择
视图集很多情况下,我们都需要在获取与创建时提供不同的序列化器,除了最粗暴的直接复制视图集定义新的路由映射,还可以通过重写getserializerclass方法实现功能
class ModelView(ModelViewSet):
...
def get_serializer_class(self):
if self.action == 'list':
return ListSer
if self.action == 'create':
return CreateSer
总结
- 视图集
- 提供了对于视图中action**行为的路由映射**定义功能
- 是一群功能视图的合集
视图集路由
对于视图集ViewSet,我们除了可以自己手动指明请求方式与动作action之间的对应关系外,还可以使用drf所提供的路由功能Routers来帮助我们快速实现路由信息,更加的方便快捷
Routers主要分如下两种
SimpleRouter
最基本的路由映射方式,只会将视图集具备的混入类功能进行路由的生成
比如我们编写一个视图集,具备有全部功能,采用ModelViewSet
class BookModelViewSet(ModelViewSet):
serializer_class = BookSerializer
queryset = Book.objects.all()
- 之后为其进行路由映射,找到路由文件在其中编写
from rest_framework import routers
# 1.实例化路由对象
router = routers.SimpleRouter()
# 2.注册生成路由
router.register('book', BookModelViewSet, basename='book')
# 3.添加路由
urlpatterns += router.urls
创建好的路由如下所示,虽然你只看到两条路由 但其实每一条路由后面都映射了可以保留的请求方式及action的映射
[
<URLPattern '^book/$' [name='book-list']>,
# 包含:获取列表get,创建一条post
<URLPattern '^book/(?P<pk>[^/.]+)/$' [name='book-detail']>
# 包含:获取一条get、更新一条put、删除一条delete
]
- 路由对象register方法参数介绍
# 1.实例化路由对象
router = routers.SimpleRouter()
# 2.注册生成路由
router.register('路由命名', 视图集, basename='路由名称前缀')
DefaultRouter
对比与SimpleRouter更加高级,包含有drf根页面的路由,不只是视图集所包含的视图部分
- 注册路由
from rest_framework import routers
# 1.实例化路由对象
router = routers.DefaultRouter()
# 2.注册生成路由
router.register('book', BookModelViewSet, basename='book')
# 3.添加路由
urlpatterns += router.urls
- 此时生成的路由
[
<URLPattern '^book/$' [name='book-list']>,
<URLPattern '^book\.(?P<format>[a-z0-9]+)/?$' [name='book-list']>,
<URLPattern '^book/(?P<pk>[^/.]+)/$' [name='book-detail']>,
<URLPattern '^book/(?P<pk>[^/.]+)\.(?P<format>[a-z0-9]+)/?$' [name='book-detail']>,
<URLPattern '^$' [name='api-root']>,
<URLPattern '^\.(?P<format>[a-z0-9]+)/?$' [name='api-root']>
]
我们看到中间还多了一些路由,是带有format正则匹配的,这些是用来获取纯粹json格式数据
<URLPattern '^book\.(?P<format>[a-z0-9]+)/?$'
[name='book-list']>,
<URLPattern '^book/(?P<pk>[^/.]+)\.(?P<format>[a-z0-9]+)/?$'
[name='book-detail']>,
<URLPattern '^\.(?P<format>[a-z0-9]+)/?$'
[name='api-root']>
比如直接通过浏览器访问接口地址,默认会返回DRF所提供的页面,但是此时数据被解析成了text/html格式,如果希望得到纯粹的json格式,那么可以利用上面DefaultRouter路由生成的新路由,直接访问如下连接,看到的就是直接的json格式返回,而不是html标签格式
http://127.0.0.1:8000/book.json
#'^book\.(?P<format>[a-z0-9]+)/?$' [name='book-list'],
- 注意,除了使用urlpatterns进行路由拼接,还可使用include进行路由分发也是可以的
path('', include(router.urls)),
自定义动作路由映射
如果是自定义编写的视图,是不会直接在SimpleRouter进行register时进行初始化的,所以需要我们再通过action装饰器进行维护
from rest_framework.decorators import action
class StuModelViewSet(ModelViewSet):
...
@action(methods=["get"],detail=False)
def id_than_1(self, request): # 获取id超过1的数据们
queryset = self.get_queryset().filter(id__gt=1)
serializer = self.get_serializer(instance=queryset, many=True)
return Response(serializer.data)
action
装饰器主要有两个参数
- methods:该参数代表请求的映射方式
- detail:该参数代表是否该视图匹配的路由是否需要具备lookupurlkwarg
现在创建的路由对象,自定义动作的路由就是这样的
'^stu/id_than_1/$'
如果detail参数为True,那么此时的路由映射出来是这样的
'^stu/(?P<pk>[^/.]+)/id_than_1/$'
- 注意:action所装饰并通过路由自动映射生成的路由字符串,id对应的路由参数位置并不是默认的最后,而是在路由前缀与视图名中间
分页
强大的 drf 还提供了对于分页的支持,可以方便快捷的进行接口的全局分页或者局部分页设置
全局分页
直接在 settings中配置即可
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS':
# 'rest_framework.pagination.PageNumberPagination',
'rest_framework.pagination.LimitOffsetPagination',
'PAGE_SIZE': 2 # 每页数目
}
配置完了如果不向用,那么就直接在视图类下使用如下属性关闭全局分页功能
class View(...):
pagination_class = None
- PageNumberPagination
可以进行直接的页码处理,返回某一页分页数据
http://127.0.0.1:8000/user/?limit=2&page=2
# limit:每页的数据大小
# page:当前的页码
- LimitOffsetPagination
可以通过连接可选的参数进行分页单页数量大小的控制,分页数据偏移的选择
http://127.0.0.1:8000/path/?limit=2&offset=2"
# limit:每页的数据大小
# offset:从某一个数据位置开始偏移
局部分页
除了默认的分页样式之外,还可以通过继承分页类的方式重写分页样式,并将其作用至局部
from rest_framework.pagination import PageNumberPagination
class StandardResultsSetPagination(PageNumberPagination):
page_size = 2 # 每页数据量
page_size_query_param = 'page_size' # 每页大小连接传递参数
max_page_size = 5 # 每页数据量最多
page_query_param = 'page' # 路由传递获取的页码参数 key 值
- 局部作用分页类,需要使用pagination_class属性
class SomeModelViewSet(ModelViewSet):
...
pagination_class = StandardResultsSetPagination
自定义分页
要创建自定义的分页序列化程序类,可以继承分页基类,重写 paginatequeryset 和 getpaginated_response 方法
- paginate_queryset:分页所要操作的数据对象
- getpaginatedresponse:分页后的实际数据,并返回一个 Response
如希望可以返回分页数据时,带上分了多少页的信息,可以重写*getpaginatedresponse*
from rest_framework.utils.urls import replace_query_param
class CustomPagination(PageNumberPagination):
def get_paginated_response(self, data):
url = self.request.build_absolute_uri()
num_pages = self.page.paginator.num_pages
return Response({
'links': {
'next': self.get_next_link(),
'previous': self.get_previous_link()
},
'count': self.page.paginator.count,
# 'num_pages': self.page.paginator.num_pages,
'num_pages': [
replace_query_param(
url, # 接口主机地址
self.page_query_param, # get传参时的页码标示
num_page # 带拼接的页码
)
for num_page in range(1, num_pages + 1) # 推导式
],
'results': data
})
过滤
过滤的功能就很简单了,可以通过给定的条件进行数据库字段查询,支持精准查询和模糊查询
- 首先安装需要支持的模块 django-filter,过滤基于该模块
pip3 install django-filter
- 使用过滤功能,首先要设置过滤功能引擎,打开 settings 配置
REST_FRAMEWORK = {
'DEFAULT_FILTER_BACKENDS':
['django_filters.rest_framework.DjangoFilterBackend']
}
- 或者还可以为使用 GenericAPIView作为基类的视图或每个视图集局部设置过滤器
from django_filters.rest_framework import DjangoFilterBackend
class UserListView(generics.ListAPIView):
...
filter_backends = [DjangoFilterBackend]
DjangoFilter 过滤
如果只需要简单的精准条件过滤,则可以 filterset_fields在视图或视图集上设置一个属性,列出要过滤的字段集
class List(generics.ListAPIView):
queryset = model.objects.all()
serializer_class = Serializer
filter_backends = [DjangoFilterBackend]
filterset_fields = ['name',...]
注意:这种方式只能是进行精准过滤,对相应字段进行精准匹配,无法做成模糊查询哦
- 如果希望完成一些模糊匹配的工作,可以自定义过滤类
from django_filters import FilterSet, rest_framework
class UserFilter(FilterSet):
name = rest_framework.CharFilter(
field_name="name", # 模型类中的字段
lookup_expr='contains' # 过滤链式条件
)
class Meta:
model = User # 模型
fields = ['name']
- 之后将自定义过滤类加持到视图类下
filter_class = UserFilter
SearchFilter 过滤
如果想要完成基本的模糊查询,可以使用另外一种过滤引擎,叫做 SearchFilter,这是一个由 rest_framework自带的过滤引擎,直接就可以实现模糊查询哦
from rest_framework import filters
class List(generics.ListAPIView):
queryset = model.objects.all()
serializer_class = Serializer
filter_backends = [filters.SearchFilter]
search_fields = ['name',...]
search_fields指明的即是一些文本字符串的字段,比如 CharField或 TextField这样的
- 还可以使用查找双下划线表示法在 ForeignKey或 ManyToManyField上执行相关查找
search_fields = ['username', 'foreignkey__field']
通过路由访问时,可以传递search参数来确定要过滤的条件
...?search=char
除此之外,字段还可以通过在字符前面添加各种字符来限制搜索行为
- '^':从开头匹配搜索。
- '=':完全匹配
- '@':全文搜索。当前仅支持 Django 的 PostgreSQL后端
- '$':正则表达式搜索。
前后联调
以下案例主要以vue为例
前后端分离的跨域问题
安装插件
pip install django-cors-headers
修改配置信息
- 注册
corsheaders
INSTALLED_APPS = [
...
'corsheaders', # 跨域
...
]
- 添加中间件
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware', # 添加跨域中间件
'corsheaders.middleware.CorsMiddleware',
'django.middleware.common.CommonMiddleware',
# 'django.middleware.csrf.CsrfViewMiddleware', # 关闭csrf验证
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
- 配置参数,允许所有源访问
CORS_ORIGIN_ALLOW_ALL = True
axios请求
首先在Vue项目的main.js中全局配置axios
import axios from 'axios' // 导入axios
axios.defaults.baseURL = "http://127.0.0.1:8000/" // 设置axios请求的默认域名,即django服务的域名
Vue.prototype.$axios = axios // 全局挂载axios
vue数据处理
vue获取数据进行渲染删除
<template>
<div>
<!-- 三、循环展示所有作者 -->
<table>
<tr v-for="author in authorList" :key="author.id">
<td>{{ author.id }}</td>
<td>{{ author.name }}</td>
<td>{{ author.gender }}</td>
<td>{{ author.age }}</td>
<td>
<!--
内层元素的事件会从内向外依次触发, 叫做冒泡机制
想要阻止冒泡事件,需要 使用 事件修饰符 .stop
-->
<button @click.stop="delAuthor">删除</button>
</td>
</tr>
</table>
</div>
</template>
<script>
export default {
name: "AuthorList",
data() {
return {
authorList: []
}
},
methods: {
// 一、get请求所有作者
getAuthorList() {
this.$axios.get('author/')
.then(resp => {
console.log(resp.data)
this.authorList = resp.data
})
},
delAuthor(id) {
this.$axios.delete('author/' + id + '/')
.then(resp => {
// 删除成功,重新请求数据,刷新页面
this.getAuthorList();
})
.catch(err => {
console.log('删除失败')
})
},
},
mounted() {
// 二、挂载,让请求自动执行
this.getAuthorList();
}
}
</script>
axios提交
创建数据
<template>
<div>
<!-- 1. 使用v-model指定从表单获取数据 -->
图书标题: <input type="text" v-model="title">
图书价格: <input type="text" v-model="price">
<!-- 3. 使用事件绑定,将 方法和按钮进行绑定 -->
<button @click="btn">添加</button>
</div>
</template>
<script>
export default {
name: "Book",
data() {
return {
title: '',
price: ''
}
},
methods: {
btn() {
// 2. 定义方法, 使用axios发送post请求,并携带参数
this.$axios.post('book/', {'title': this.title, 'price': this.price})
.then(resp => {
// 添加成功,输出响应数据
console.log(resp.data)
})
.catch(err => {
// 添加失败,输出错误信息
console.log(err.response.data)
})
}
}
}
</script>
修改数据
<template>
<div>
<!-- 修改之前,需要有原始数据 -->
<!-- 一、修改图书之前,给表单设置默认值, 原本的图书数据 -->
<!-- 二.修改同样也需要获取用户输入的新数据 -->
图书标题: <input type="text" v-model="book.title">
图书价格: <input type="text" v-model="book.price">
<!-- 四、对按钮绑定事件 -->
<button @click="updateBook">修改</button>
</div>
</template>
<script>
export default {
name: "BookUpdate",
data() {
return {
id: 1,
book: {
title: '',
price: ''
}
}
},
methods: {
// 1.1 获取id对应的图书数据
getBook() {
this.$axios.get('book/' + this.id + '/')
.then(resp => {
// 请求成功,将请求到的图书数据赋值给data中的变量,
// 而表单和data中的数据进行双向绑定
// 给data中的数据设置默认值,表单也会有默认值
this.book.title = resp.data.title
this.book.price = resp.data.price
})
},
// 三. 定义方法,使用put提交数据
updateBook() {
this.$axios.put('book/' + this.id + '/', this.book)
.then(resp => {
console.log(resp.data)
})
}
},
mounted() {
// 1.3 挂载
this.getBook();
}
}
</script>
状态保持
前后端分离情况下的状态保持
除了使用vuex在vue中的标准解决方案外,还有类似浏览器的内部存储机制,比如
localStorage.setItem('user', this.username) // 用户名存入localStorage,以做状态保持
let username = localStorage.getItem('user') // 取出user信息,可以判断用户是否登录
限流
匿名用户全局限流
可以对接口访问的频次进行限制,以减轻服务器压力。特别是限制爬虫的抓取。
可以在配置文件中,使用DEFAULTTHROTTLECLASSES 和 DEFAULTTHROTTLERATES进行全局配置
REST_FRAMEWORK = {
'DEFAULT_THROTTLE_CLASSES': (
# 限制所有匿名未认证用户,使用IP区分用户
'rest_framework.throttling.AnonRateThrottle'
),
'DEFAULT_THROTTLE_RATES': {
# 可以使用 second, minute, hour 或day来指明周期
'anon': '3/minute',
'user': '5/minute'
}
}
匿名用户局部限流
视图中使用throttle_classes属性设置限流用户类型
from rest_framework.generics import ListAPIView
from rest_framework.throttling import AnonRateThrottle
from .serializer import UserSerializer, User
class UserView(ListAPIView):
queryset = User.objects.all()
serializer_class = UserSerializer
throttle_classes = [AnonRateThrottle] # 指明针对匿名用户进行限流,限流频率全局配置
在项目配置文件中针对用户类型设置具体频率
REST_FRAMEWORK = {
'DEFAULT_THROTTLE_RATES': {
# 可以使用 second, minute, hour 或day来指明周期
'anon': '3/minute',
'user': '5/minute'
}
}